ServiceNow CMDB Enrichment Best Practices
Synchronizing your CMDB data from ServiceNow with BigPanda allows you to enrich your inbound alerts with contextual information. This helps improve correlation, MTTR, reporting accuracy, and increases consistency within the platform.
ServiceNow CMDB basics
Looking for just the basics? Check out the ServiceNow CMDB Enrichment one page document in BigPanda University!
Before You Start
The information in this document is for reference purposes only and is not intended to take the place of architectural decision-making and engineering advice from a BigPanda expert. Considerations must be made before configuration should be attempted. Further configuration information is available in the ServiceNow CMDB documentation .
CMDB enrichment should be done after or in conjunction with Data Normalization .
Considerations Before Making Changes
Before making any changes to the BigPanda ServiceNow integration:
You must switch the Application Scope to BigPanda.
Ensure you have only one browser tab open on the BigPanda ServiceNow integration Configuration page to prevent issues. This prevents:
out-of-sync errors caused by browser window timeouts
unsaved configuration changes due to non-BigPanda Application Scopes interfering with your configuration tab or window. Often, errors happen when multiple browser windows with different application scopes selected are open.
We recommend making any changes in a lower environment (non-prod, sandbox, development BigPanda org) first to familiarize yourself with the process before executing them in your production BigPanda instance.
If you have questions about the configuration, please contact BigPanda support ([email protected]).
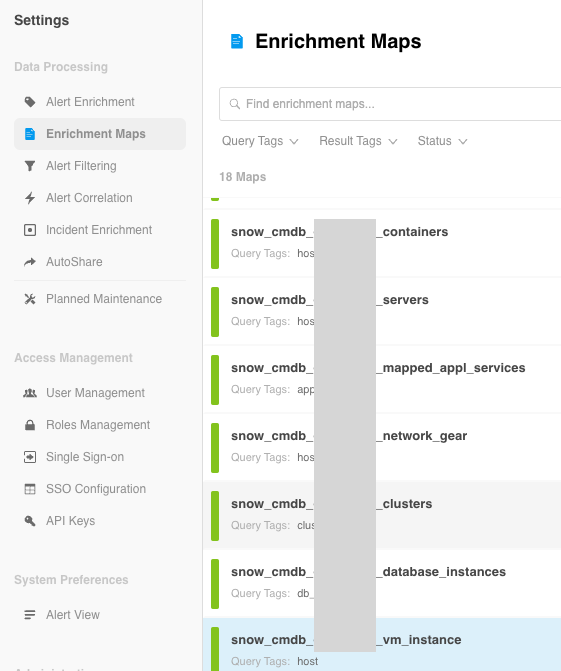
Enrichment Map Example
Data synchronized from your ServiceNow CMDB will appear in Enrichment Maps within BigPanda. These enrichment maps begin with “snow_cmdb_” and end with your “BigPanda Map Name”, such as “_network_gear”.
When finished your Enrichment tables might look something like this:
Synchronization may take several minutes to hours to complete depending on the size of each CI Class table.
Trigger it once and watch the synchronization happen in the ServiceNow Application Logs.
Best Practices
Incomplete or inaccurate information in your CMDB can cause inconsistencies in BigPanda. Remember the old saying, “Garbage in = Garbage out.” If there are discrepancies in your CMDB, we recommend resolving them before integrating with BigPanda.
When implementing this integration, we recommend you only export columns that are useful for improving correlation or enhancing the detail for manual triage processes. Be sure to review other enrichment sources that provide details before implementing any changes.
The exported column headers and synchronization update times are visible within BigPanda at Settings > Enrichment Maps .
Manual CMDB Synchronization
You can manually trigger a CMDB synchronization to verify newly configured tables.
To set up a manual trigger:
In ServiceNow, go to All > BigPanda > CMDB > CMDB Processing Schedule.
Set the run to On Demand and Save.
In the upper right corner, click the Execute Now button. This manually starts the sync.
After the sync has completed, set the Run state to Periodically and set your Preferred Run Time.
Trigger CMDB Synchronization
To trigger CMDB synchronization, you need to make a change to a table’s data. If no changes have occurred, the synchronization step will not be triggered, and this will be noted in the ServiceNow Application Logs.
If you change the configuration without performing the manual synchronization steps described above, you will need to wait until the next time the table has changed before you can see and verify the table in BigPanda. This could take hours or up to several days. Manually changing a record in the table will ensure the sync runs at the next scheduled interval.
Synchronization Settings
We recommend using the following synchronization settings:
Name | Recommended Setting | Notes |
|---|---|---|
Page Size | 1000 | This is the default setting and recommended maximum. |
Max Retries | 1 | If the CMDB integration has failed, it will try again once. If that fails, it will stop until the next execution interval. Setting this value low reduces unnecessary overhead on both BigPanda and ServiceNow. For example, if there are network communication issues between BigPanda and ServiceNow, a disruption from AWS, or a similar issue, you won’t want it to keep retrying continuously. The system will synchronize on the next execution interval, so there will only be a short period of time where enrichment data might be partially out of sync. |
Max Pages | 2500 | This is the recommended maximum page count. The maximum size is not the continually expected sync size, but the maximum that it will attempt to process at once. Typically, your sync will be between 200 and 500 pages and will take less than 20 minutes to complete. |
Retry Interval | 120 (seconds) | This value is how quickly the system will attempt a retry if there is an issue with CMDB sync. We recommend setting this to a minimum of 2 minutes and a maximum of 10 minutes. Keep in mind that if the sync has failed, retrying immediately will also generally fail. |
Execution Interval | 24 (hours) | We generally recommend 24-hour sync intervals, as this meets the requirements of the majority of customers. |
Configuration Examples
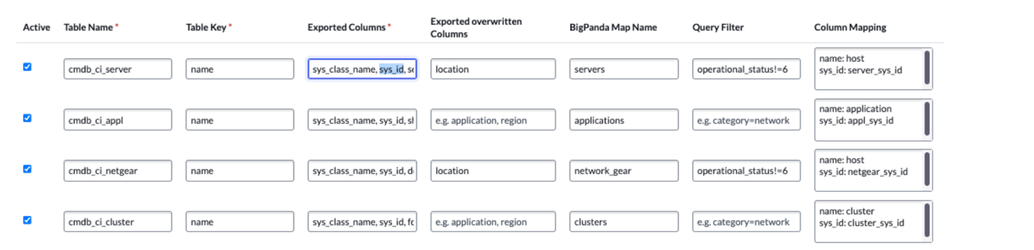 |
You can use the examples below to populate the CMDB table export configuration. Please note that this list is not meant to be exhaustive. We recommend you refer to the tables and CMDB Classes used in your CMDB before taking steps to configure.
Below is a list of recommended tables in ServiceNow for use with enrichment.
The tables you decide to use should depend on the data you need for enrichment in BigPanda and the quality of the data in those tables and fields.
The list contains the default table names from a standard ServiceNow deployment. Your table names and data alignment may vary.
Recommended
Table Name | Table Label | Table Description |
|---|---|---|
cmdb_ci_appl | Application | A collection of files and data that deliver a service and manage business processes. |
cmdb_ci_service | Service | IT service that directly supports a business process (ITIL). |
cmdb_ci_business_app | Business Application | All business applications. |
cmdb_ci_server | Server | Base class for all types of servers. |
cmdb_ci_netgear | Network Gear | Extension of the Hardware table, that captures network equipment such as router, switch, hub, gateway, and bridge. |
cmdb_ci_storage_device | Storage Device | Base table for block storage devices such as DAS, SAN, and NAS. |
cmdb_ci_database | Database | Organized collection of data such as the set of files where data is stored, the reason for a database, and the metadata. |
cmdb_ci_msd | Mass Storage Device | Physical storage device. |
Advanced
Table Name | Table Label | Table Description |
|---|---|---|
cmdb_ci_service_discovered | Mapped Application Service | Application services, created by the Manual service population method. For each application service, there is a container CI record that models the application service. |
cmdb_ci_cluster | Cluster | Logical group of computing resources bound together by software in order to function as one logical computing resource. |
cmdb_ci_vm | Virtual Machine HyperVisor | Hypervisor software. |
cmdb_ci_vm_instance | Virtual Machine Instance | Generic virtual machines information. |
cmdb_ci_lb | Load Balancer | Server functioning as a load balanacer. |
cmdb_ci_lb_pool | Load Balancer Pool | Collection of host-to-port mappings to be balanced. |
Special Cases
Table Name | Table Label | Table Description |
|---|---|---|
cmdb_ci_docker | Docker Container | Docker containers (a runtime instance of a Docker image). |
cmdb_ci_db_catalog | Database Catalog | Metadata which defines database objects such as base tables, views (virtual tables), synonyms, value ranges, indexes, users, and user groups, for a specific database instance. |
Base Fields
Each table will have its own unique set of fields that may or may not be valuable depending on the object type, the data quality of the table, and the enrichment needs in BigPanda. We typically see the following base fields used in most maps, but you can bring in any field that is needed.
Field | Tag map | Description |
|---|---|---|
name | host | Usually the query value for the map. |
sys_id | object_sys_id | The ServiceNow object sys_id, typically prefixed with the object type. (i.e., server) |
sys_class_name | object_sys_class_name | The class or type of object. |
support_group | object_assignment_group | The assignment group that triages incidents for this object. |
Other tags that are often exported include ip_address, model, location, criticality, used_for, sla, department, category, priority, etc
Be sure to choose the exported columns that are populated and used by the CI Class. This list isn’t exhaustive; please refer to the CI Class definition inside of ServiceNow.
You can see what is defined per class via the CMDB CI Manager view within ServiceNow.
Best practice
Mapping assignment, ownership, and support is important. Review your configuration and ensure these fields are set based on your use case. Your CMDB tables may be affected by plugin applications, feature adoption, and age of creation.
Query Filter
The query filter field defines filtering for including or excluding certain rows from an export. This field is optional.
Entering nothing in this field will include all entries from the system class table defined. We recommend excluding retired systems from the CMDB export, however, you might find it useful to keep those synchronized. If you need to filter which table rows are synchronized to BigPanda, you can choose the operational status and opt-in (“=”) to include only in service values. Alternatively, you can use opt-out (“!=6”) to only exclude retired status values.
Column Mapping
The column mapping section is used to define how the exported columns will be mapped to tags when they are created in BigPanda.
Typically we see these tags defined to align with the standard tags set in the Data Normalization process, but some customers choose to differentiate these tags with prefixes denoting their source and/or object type. Below are examples of different types of column mappings:
Normalized Tag | ServiceNow Prefix Tag | Object Prefix Tag | ServiceNow and Object Prefix Tag |
|---|---|---|---|
assignment_group | sn_assignment_group | app_assignment_group | sn_app_assignment_group |
sys_id | sn_sys_id | app_sys_id | sn_app_sys_id |
(Optional) ServiceNow Update Set with Base Tables and Default Column Mapping
A BigPanda update set is available that will set the CMDB configuration section with the base tables and the recommended defaults for exported tables, map name, query filters, and column mapping. Contact your account team for access.
(Optional) Additional Table Exports
Not every potential CI Class is included here, only examples. Be sure to consider all of the different CI Class types that might be defined in your ServiceNow CMDB.
Additional table exports are often required for systems that don’t fall under the reference categories defined in this document. A good example is “Mass Storage Devices.”
Using the above formatting, you should be able to quickly gather the necessary details to export additional tables in the same manner. If you’re unsure, you can consult the BigPanda support team, the related documentation, or your BigPanda Account Team. Further guidance may be available and BigPanda Professional Services might also be able to assist you with your configuration.
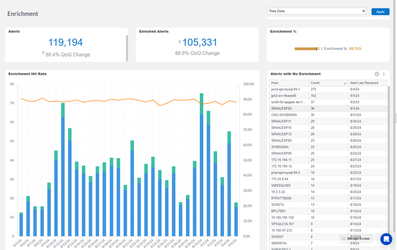
Measuring Success
You can use the Unified Analytics Enrichment dashboard to track the percentage of alerts being enriched and the enrichment rate change over time. It also provides you with a top list of alerting objects that are not being enriched. This list can be used as a starting point for improving CMDB enrichment by identifying objects missing from the CMDB or additional enrichment maps that need to be configured for use in BigPanda enrichment.
 |