Raw Data ETL Schema
Legacy ETL platform end-of-life
The Open Analytics Hub is now available, allowing you to directly query and export your BigPanda raw data from Snowflake.
As part of BigPanda's commitment to delivering modern, cost-effective, and scalable data solutions, the legacy ETL data platform backed by Redshift will be deprecated and transitioned to the new platform.
See the Open Analytics Hub documentation for more information about accessing your data. Contact your BigPanda account team if you have any questions.
BigPanda maintains raw data in standard objects available for export as needed for reporting or building predictive models.
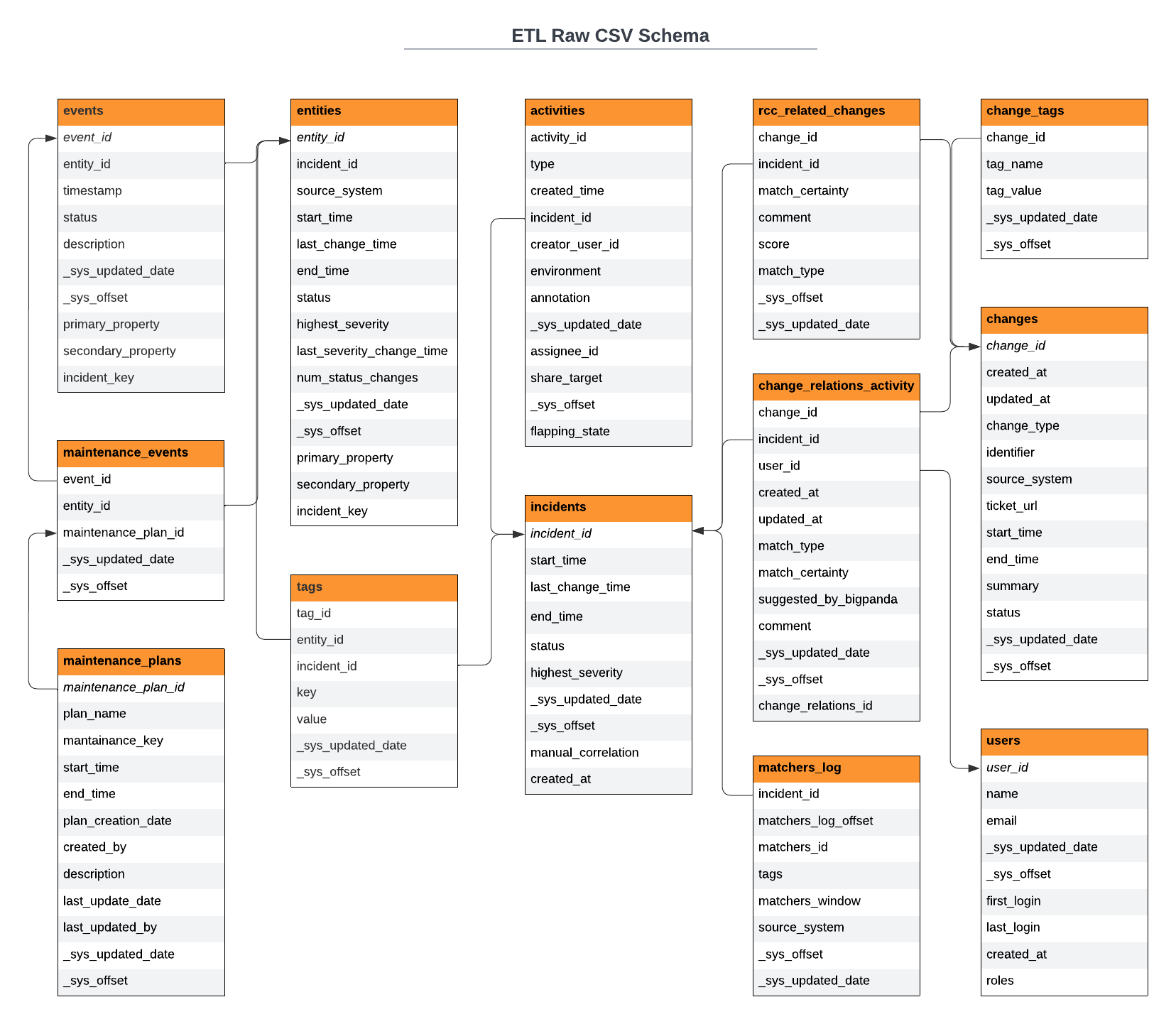 |
ETL Raw CSV Schema
The raw data can be accessed through the BigPanda ETL pipeline, or can be exported in CSV format and processed through your own external tools.
Some columns may appear in different order when accessed through a reporting tool or from the ETL Warehouses. When using the Raw CSV files, refer to the CSV Index # Column to ensure the correct fields are parsed.
CSV export
The exported CSV will not have headers and the source data may change at any time. Ensure your ETL process is able to handle changes in the CSV.
In the ETL process, additional columns may be added with ETL information:
_sys_import_time - the timestamp of the sync
_sys_execution_id - The unique identifier of the sync execution
To learn more about configuring an ETL sync for your data, see the ETL Sync Documentation.
The ETL schema tables can also be downloaded in an XLSX file. Contact the support team for a copy of the file.
Primary identifiers
When using the BigPanda ETL, incident_id and tag_id are typically the primary identifiers. The tables below have bolded the column names that make up the primary keys for each reporting table
activities
A single action a user performed in BigPanda.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
activity_id | The unique identifier of the Activity | String | 0 | 0 |
type | The type of activity | String | 1 | Format is: incident#ACTION Assigned, Commented, External-Resolve, Manual-Resolve, Merge, Shared, Snoozed, Split, Unassigned, Unsnoozed, Become-Flapping |
created_time | The unix time the action was taken | Float | 2 | |
incident_id | The unique identifier of the incident the action was taken on | String | 3 | |
creator_user_id | The unique identifier of the user who performed the activity | String | 4 | |
environment | The name of the environment the activity took place in | String | 5 | |
annotation | The comment that was included with the activity | String | 6 | |
_sys_updated_date | The last time the database record was updated in unix time | Float | 7 | |
assignee_id | The user assigned by the activity | String | 8 | “Assign”-activity specific |
share_target | The name of the system the related incident was shared to | String | 9 | “Share”-activity specific Can be used to filter |
_sys_offset | System field - can be ignored | Integer | 10 | |
is_flapping | Whether or not the related incident is in the flapping state | Boolean | 11 | |
_sys_import_time | The time of the last import to redshift | String | This is the field used for redshift syncing |
change_relations_activity
Actions in BigPanda that mark a change as related to an incident.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
change_id | The unique identifier of the related change | String | 0 | |
incident_id | The unique identifier of the related incident | String | 1 | |
user_id | The unique identifier of the user who performed the action | String | 2 | |
created_at | The unix time when the change relation was marked in BigPanda | Float | 3 | |
updated_at | The unix time when the change relation was last updated in BigPanda | Float | 4 | |
match_type | The type of match | String | 5 | MANUAL |
match_certainty | The confidence level of the match | String | 6 | None, Suspect, or Match |
suggested_by_bigpanda | Not currently in use | Boolean | 7 | |
comment | A comment included with the action | String | 8 | |
_sys_updated_date | The last time the database record was updated in unix time | Float | 9 | |
_sys_offset | System field - can be ignored | Integer | 10 | |
change_relations_id | The unique identifier of the relation | String | 11 | |
_sys_import_time | The time of the last import to redshift | String | This is the field used for redshift syncing |
changes
A change that was sent to and processed by BigPanda.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
change_id | The unique identifier of the change | String | 0 | |
created_at | The unix time when the change was created in BigPanda | Float | 1 | |
updated_at | The unix time when the change was last updated in BigPanda | Float | 2 | |
change_type | Whether a new change record was created or an existing change record was updated. | String | 3 | change#create, or change#update |
identifier | System identifier for the change | String | 4 | |
source_system | The system that sent this change to BigPanda | String | 5 | |
ticket_url | The URL to the change in the change control system, if applicable | String | 6 | |
start_time | The unix time for the change start | Float | 7 | |
end_time | The unix time for the change end | Float | 8 | |
summary | A summary of the change | String | 9 | |
status | The status of the change | String | 10 | Planned, In Progress, Done, or Canceled |
_sys_updated_date | The last time the database record was updated in unix time | Float | 11 | |
_sys_offset | System field - can be ignored | Integer | 12 | |
_sys_import_time | The time of the last import to redshift | String | This is the field used for redshift syncing |
change_tags
A tag related to a single change in BigPanda.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
change_id | The unique identifier of the change | String | 0 | |
tag_name | The tag name | String | 1 | |
tag_value | The tag value | String | 2 | |
_sys_updated_date | The last time the database record was updated in unix time | Float | 3 | |
_sys_offset | System field - can be ignored | Integer | 4 | |
_sys_import_time | The time of the last import to redshift | String | This is the field used for redshift syncing |
entities
Each entity is a single aggregated alert in BigPanda. Each entity appears as their own row in the BigPanda timeline view. If incidents are merged, the incident id will be updated to the destination incident id for all merged entities.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
entity_id | The unique identifier of the entity | String | 0 | |
incident_id | The unique identifier of the incident to which this entity belongs | String | 1 | |
source_system | The monitor system that sent this alert | String | 2 | |
start_time | The unix time the alert started | Float | 3 | |
last_change_time | The unix time for the last change made to an alert | Float | 4 | |
end_time | The unix time for the resolution of the alert | Float | 5 | |
status | The current status of the entity | String | 6 | Ok, Critical, or Warning |
highest_severity | The highest status of the entity | String | 7 | Can be used to find entities that were critical at any point |
last_severity_change_time | The unix time for the last severity change | Float | 8 | |
num_status_changes | The number of times the entity has changed status | Integer | 9 | Limited to ~70 events Changes to the “ok” statuses are not counted |
_sys_updated_date | The unix time that BigPanda extracted this record to the ETL pipeline | Float | 10 | |
_sys_offset | System field - can be ignored | Integer | 11 | |
primary_property | The main title of the related incident in the UI | String | 12 | The tag key treated as the primary property |
secondary_property | The secondary title of the related incident in the UI | String | 13 | The tag key treated as the secondary property |
incident_key | A unique id BigPanda uses to recognize if two events are related to each other | String | 14 | Splice the primary property’s value and the secondary property’s value |
_sys_import_time | The time of the last import to redshift | String | This is the field used for redshift syncing |
events
A raw event arriving in BigPanda. Only status changes are included: for instance, if a duplicate event for an already critical alert fires, it will not appear in this table.
Column Name | Descriptions | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
event_id | The unique identifier of the event | String | 0 | |
entity_id | The unique identifier of the entity to which this event belongs | String | 1 | |
timestamp | The unix time of the event | Float | 2 | |
description | The raw description sent with the event | String | 4 | |
status | The status for the event | String | 3 | |
_sys_updated_date | The last time the database record was updated in unix time | Float | 5 | |
_sys_offset | System field - can be ignored | Integer | 6 | |
primary_property | The main title of the event in the UI | String | 7 | |
secondary_property | The secondary title of the incident in the UI | String | 8 | |
incident_key | A unique id BigPanda uses to recognize if two events are related to each other | String | 9 | |
_sys_import_time | The time of the last import to redshift | String | This is the field used for redshift syncing |
incidents
A single BigPanda incident.
Column Name | Definition | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
incident_id | The unique identifier of the incident | String | 0 | |
start_time | The unix time the incident started | Float | 1 | |
last_change_time | The unix time for the last status change | Float | 2 | |
end_time | The unix time for the resolution of the incident | Float | 3 | |
status | The current status of the incident | String | 4 | Ok, Critical, or Warning |
highest_severity | The highest status of the incident | String | 5 | Can be used to differentiate incidents that were critical at any point |
_sys_updated_date | The last time the database record was updated in unix time | Float | 6 | |
_sys_offset | System field - can be ignored | Integer | 7 | |
_sys_import_time | The time of the last import to redshift | String | This is the field used for redshift syncing | |
manual_correlation | Whether the incident has been manually merged or split | String | 8 | |
created_at | System field - can be disregarded | String | 9 | System field - can be disregarded |
maintenance-events
A single event that matched a maintenance plan. Maintenance_plan was the old naming convention for maintenance plans V1.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
event_id | The unique identifier of the incoming event | String | 0 | |
entity_id | The unique identifier of the entity to which this event belongs | String | 1 | |
plan_id | The unique identifier of the plan that this event matches | String | 2 | |
timestamp | The unix time of the event | Float | ||
_sys_updated_date | The last time the database record was updated in unix time | Float | 3 | |
_sys_offset | System field - can be ignored | Integer | 4 | |
_sys_import_time | The time of the last import to redshift | String | This is the field used for redshift syncing |
maintenance-plans
A single maintenance plan in BigPanda. Maintenance_plan was the old naming convention for maintenance plans V1.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
maintenance_plan_id | The unique identifier of the maintenance plan | String | 0 | |
plan_name | The name of the plan | String | 1 | |
mantainance_key | The key of the maintenance plan | String | 2 | Displayed in the UI |
start_time | The unix time when the plan will start | Float | 3 | |
end_time | The unix time when the plan will end | Float | 4 | |
plan_creation_date | The unix time that the plan was created | Float | 5 | |
created_by | The unique identifier of the user who created the plan | String | 6 | |
description | A brief summary of the plan | String | 7 | |
last_update_date | The unix time when the plan was last updated | Integer | 8 | |
last_updated_by | The unique identifier of the user who last updated the plan | String | 9 | |
_sys_updated_date | The last time the database record was updated in unix time | Float | 10 | |
_sys_offset | System field - can be ignored | Integer | 11 | |
_sys_import_time | The time of the last import to redshift | Float | This is the field used for redshift syncing |
matchers_log
The correlation patterns that matched and applied to a single BP incident
Column Name | Definition | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
incident_id | The unique identifier of the incident | String | 0 | |
matchers_log_offset | System field - can be ignored | Integer | 1 | |
matchers_id | ID of correlation pattern (can be input into a URL) | String | 2 | |
tags | An array of tags applied by the correlation patterns | Array of Strings | 3 | |
matchers_window | Max time window to correlate alerts | Integer | 4 | |
source_system | The system that sent this change to BigPanda | String | 5 | |
_sys_offset | System field - can be ignored | Integer | 6 | |
_sys_updated_date | System field - can be ignored | Integer | 7 | |
_sys_execution_id | System field - can be ignored | String | ||
_sys_import_time | The time of the last import to redshift | Float | This is the field used for redshift syncing |
tags
All tags of an entity with normalized fields. Tag values appear on their own row in columns for each entity.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
tag_id | The unique identifier of the tag | String | 0 | |
entity_id | The unique identifier of the entity | String | 1 | |
incident_id | The unique identifier of the incident | String | 2 | |
key | Tag name in system | String | 3 | |
value | Tag value | String | 4 | |
_sys_updated_date | The last time the database record was updated in unix time | Float | 5 | |
_sys_offset | System field - can be ignored | Integer | 6 |
user
A single BigPanda user.
Column Name | Description | Data Type | CSV Index # | Notes |
|---|---|---|---|---|
user_id | The unique identifier of the user | String | 0 | |
name | The in-system name of the user | String | 1 | |
The email of the user | String | 2 | ||
_sys_updated_date | The last time the database record was updated in unix time | Float | 3 | |
_sys_offset | System field - can be ignored | Integer | 4 | |
first_login | The unix time of the user’s first login to BigPanda | Float | 5 | |
last_login | The unix time of the user’s last login to BigPanda | Float | 6 | |
created_at | The unix time when the user was created in BigPanda | Float | 7 | |
roles | The list of roles assigned to this user | String | 8 | |
_sys_import_time | The time of the last import to redshift | Float | This is the field used for redshift syncing |
Next Steps
Learn how to set up the ETL Sync
Dig into additional reporting options with BigPanda Analytics