Open Analytics Hub
The BigPanda Standard Data Model uses transformed data tables for report metrics and data relationship mapping. These tables are built based on the life cycle of incidents within BigPanda.
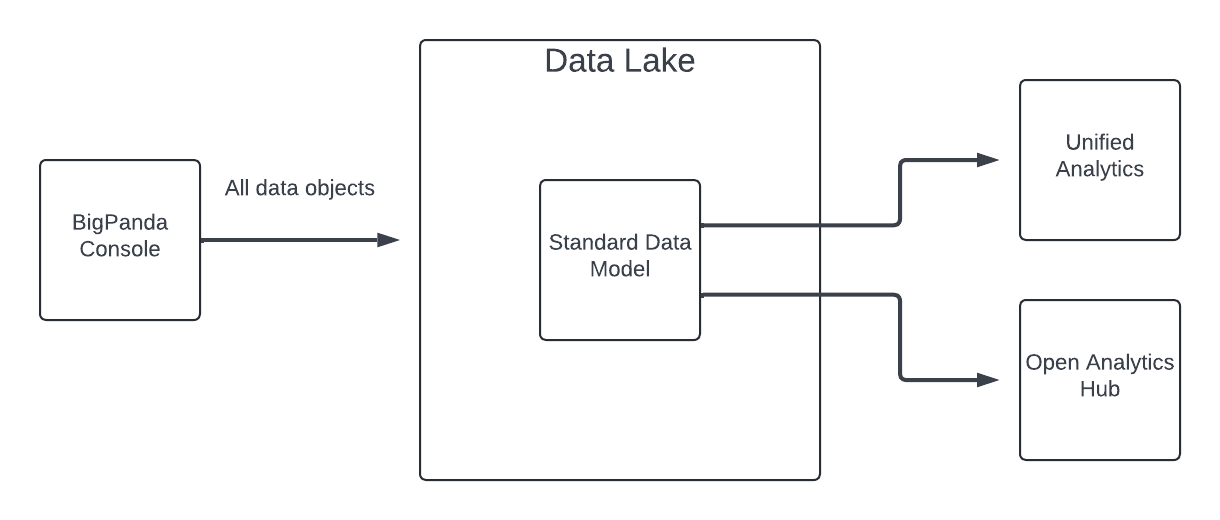
If your organization is using SDM, you can access the Open Analytics Hub to directly query and export your BigPanda raw data from Snowflake, which powers Unified Analytics. You can then combine it with your other operational data, build your own analyses using external tools, and control the structure of your data in a way that best suits your organization's needs.
Key Features
Create custom queries in Snowflake using SQL to build flexible analyses of your data.
Leverage the transformed dataset of the Standard Data Model (SDM) using the tool of your choice.
Export data from Snowflake in a standard format to external applications and combine it with other operational data.
How it Works
BigPanda’s Standard Data Model (SDM) defines the data elements available for reporting on BigPanda events. SDM is a combination of unique data tables that evaluate aspects of the BigPanda pipeline to define a uniform dataset consolidated into a single view.
Your raw data is stored within Snowflake. If your organization has migrated to SDM, you can use the Open Analytics Hub to directly access your data from Snowflake. Within the Open Analytics Hub, you can perform queries and export your data without using Unified Analytics.
Open Analytics Hub
The Open Analytics Hub environment consists of databases and virtual warehouses. A database is a physical storage space where data is secured, and a warehouse is the data processing unit where you can query the data. Each organization using the Open Analytics Hub has access to its own virtual warehouse.
The Open Analytics Hub uses secure data sharing. All data sharing happens via a unique services layer and metadata store. BigPanda customers who have access to Snowflake already can request a data share using their existing account. Customers without Snowflake accounts can request a Snowflake Reader account to access their data.
Data refresh
Data in the Open Analytics Hub is refreshed every 24 hours.
Access the Open Analytics Hub
If your organization has an existing Snowflake account in the AWS_US_WEST_2 or AWS_EU_CENTRAL_1, you can use the Open Analytics Hub's secure data share feature to retrieve and integrate the data with your existing account.
If you already have a Snowflake account, contact BigPanda support and provide your username and the region you are using to access Snowflake.
For organizations in a different region or without a Snowflake account, BigPanda provides access to two Snowflake Reader user accounts that you can use to explore and export your data in the Open Analytics Hub. To request access, contact BigPanda support.
Snowflake Reader Account Roles
BigPanda Support will provide two Snowflake Reader user accounts, one for each default role.
Two default roles are available for Snowflake Reader user accounts:
Account type | Description |
|---|---|
| Able to manage network policy and multi-factor authentication. |
| Able to view, query, and export data. |
Navigate the Open Analytics Hub
Once access to your Open Analytics Hub account has been set up, you can log in using the link provided by BigPanda support.
Open Analytics Hub link
The Open Analytics Hub uses a different link than the BigPanda platform. We recommend bookmarking the link provided to you by the BigPanda Support team.
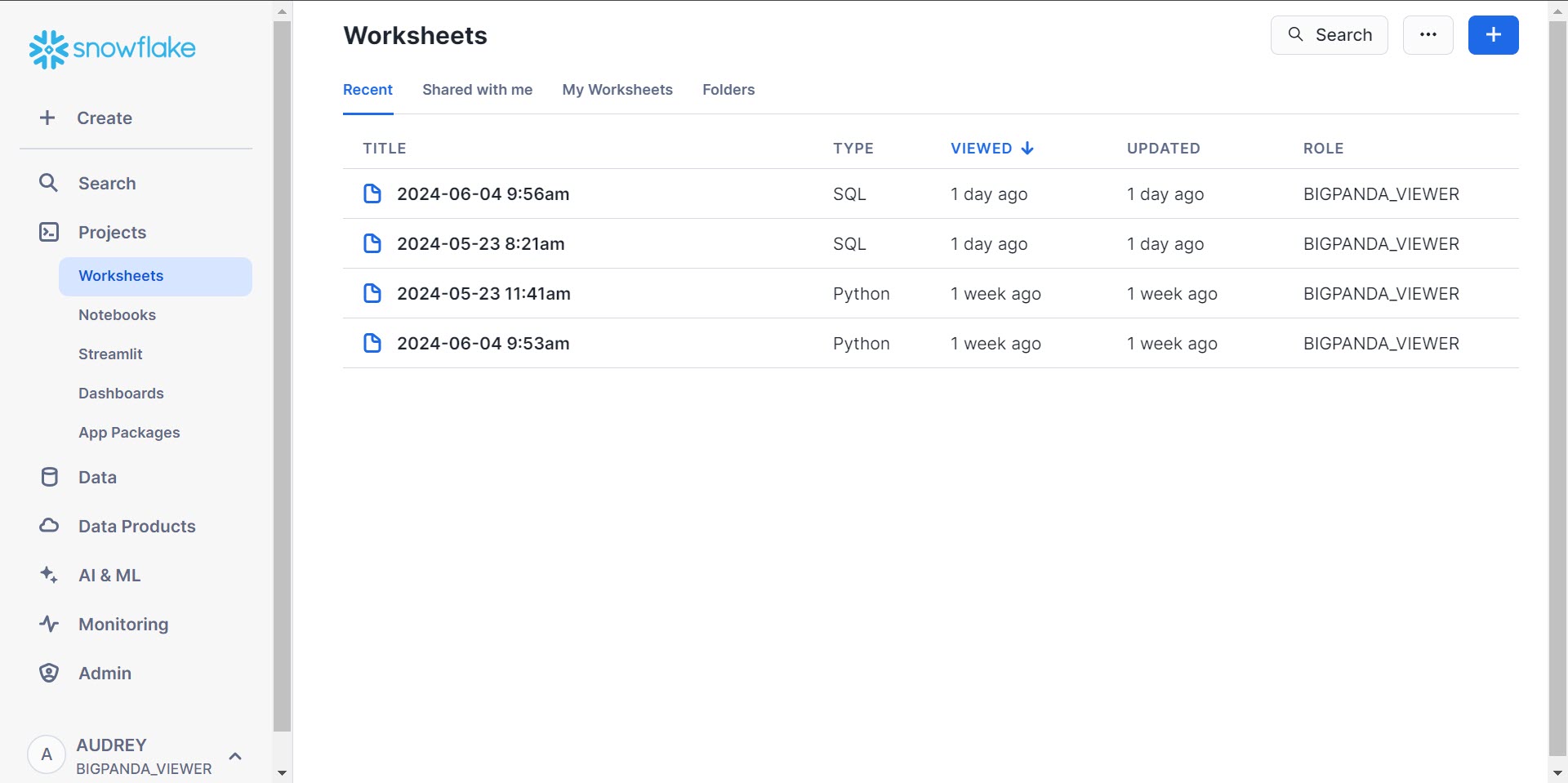
The panel on the left side of the screen allows you to navigate the modules of the Open Analytics Hub. The most commonly used are the Projects and Datamodules. Depending upon your user role, you may not have access to all modules or sections.
Open Analytics Hub
Module Name | Description |
|---|---|
Search | Contains Universal Search, where you can use natural language to search your tables, worksheets, databases, and Snowflake's marketplace and documentation. See Snowflake's Search Snowflake objects and resources for more details. |
Projects | Provides access to your Worksheets, Notebooks, and Dashboards. Streamlit and App Packages are not available for Snowflake reader accounts. |
Data | Contains your databases, where you can see details about your tables and preview your data. |
Data Products | Provides access to the Private Sharing feature, where you can access the databases that BigPanda shared with your Snowflake reader account. The Marketplace, Apps, Provider Studio, and Partner Connect features of this module are not available for Snowflake reader accounts. |
AI & ML | Features of this module are not available for Snowflake reader accounts. |
Monitoring | Shows the history of queries, copies, and tasks performed within the Open Analytics Hub. |
Admin | Contains consumption history, user management, and role management. |
Account | Contains your account settings, console appearance preferences, and Snowflake documentation. |
Preview Your Data
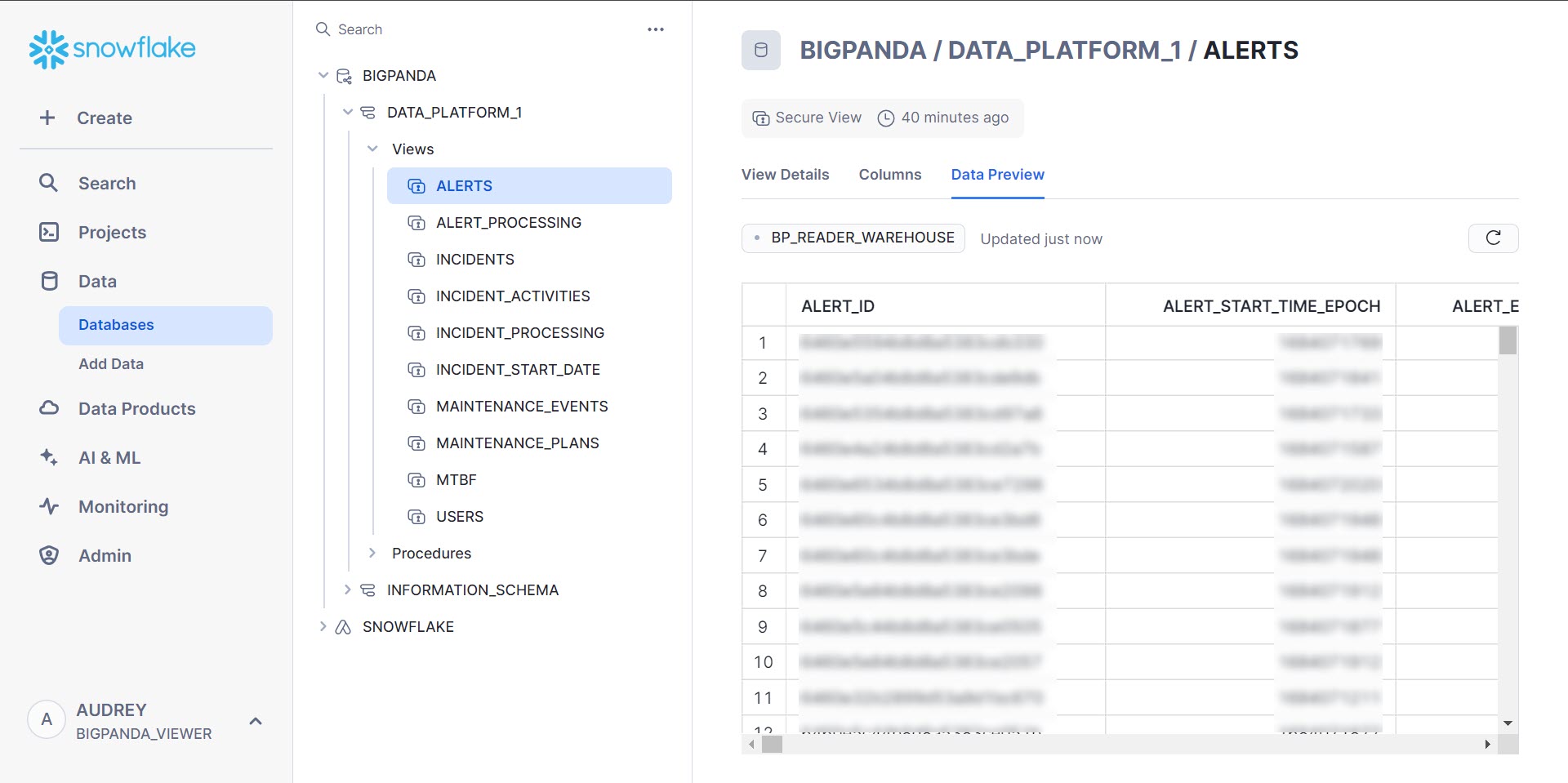
Within the Data module in the Open Analytics Hub, you can preview your data and the table columns available to you. The first 100 rows of data are visible within the preview.
Data Preview
To preview your data:
In the Open Analytics Hub left-side navigation panel, select Data > Databases.
In the center panel, select BigPanda > [Your organization name] > Views.
Select the table you would like to view.
In the panel on the right side of the screen, select the Data Preview column.
(Optional) In the data preview table, click ... at the top of a column to manipulate the data. Depending upon the type of data in the column, the following options may be available:
Sort in ascending or descending order
Increase or decrease the decimal precision
Show thousands separators in numbers
Display the data in percentages
Query Your Data
SQL Queries
Knowlege of SQL is required to query data in the Open Analytics Hub.
Snowflake supports standard SQL, including a subset of ANSI SQL:1999 and the SQL:2003 analytic extensions. Snowflake also supports common variations for a number of commands where those variations do not conflict with each other.
To query your data:
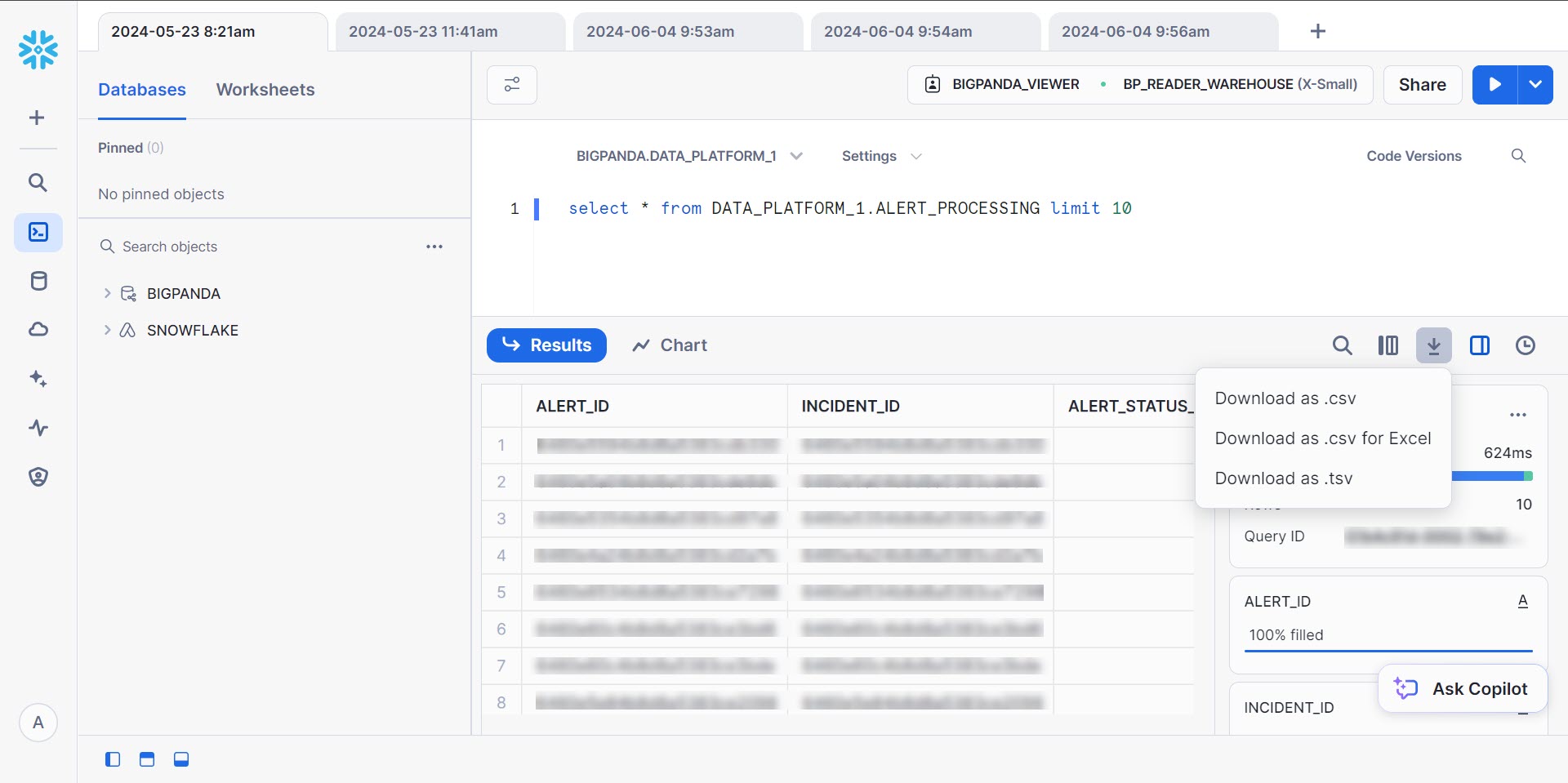
Sign in to the Open Analytics Hub and click +Create.
From the menu, select SQL Worksheet.
In the database selection dropdown, select BIGPANDA > [Your organization name].
Type your query into the screen. When you are finished, click the blue plus sign icon to run your query. The results will appear at the bottom of the screen.
(Optional) Click the download icon to download the results of your query. Results can be downloaded as .csv, .csv for Excel, or .tsv.
Querying Data
See Snowflake's Query Data documentation for more information.
Snowflake Reader Credits
Each organization has a set number of credits available to them in Snowflake Reader. Each time you perform a query in the Open Analytics Hub, a credit is used.
If your organization exceeds the number of credits allotted, an error message will appear when you attempt to perform a query. If you encounter this error, contact the BigPanda support team to discuss potentially increasing your number of available credits.
Data Unloading
Snowflake supports bulk unloading data from a database table into flat, delimited text files. If your organization uses Amazon Web Services (AWS) S3 buckets for storing and managing your data files, you can unload data into your existing buckets.
You can use the COPY INTO <location> command to unload data from a table directly into a specified S3 bucket. See Snowflake's Unloading data directly into an S3 bucket documentation for instructions.
Unloading data
To unload data into an S3 bucket, your AWS administrator must grant Snowflake access to your account. See Snowflake's Allowing the Virtual Private Cloud IDs documentation for instructions.
Export Data
Data from the Open Analytics Hub can be exported to a variety of external tools.
To connect tools to Snowflake, you'll need to set up an integration. See the documentation below for instructions for specific providers:
Connect a tool to Snowflake
You can use the Connect a tool to Snowflake option to find the settings you can use to configure drivers, clients, or third-party applications. See the Snowflake documentation for more information.
Snowflake Connector for Python
The Snowflake Connector for Python provides an interface for developing Python applications that can connect to Snowflake and perform all standard operations. It provides a programming alternative to developing applications in Java or C/C++ using the Snowflake JDBC or ODBC drivers.
To install the latest Snowflake Connector for Python, use:
pip install snowflake-connector-python
The source code for the Python driver is available on GitHub.
See the Connecting to Snowflake with the Python Connector documentation for detailed instructions.
Python version
The Snowflake Connector requires Python version 3.8 or later.
For a list of the operating systems supported by Snowflake clients, see Operating system support.
Load to an S3 Bucket Using the Python Connector
You can use the Snowflake Connector for Python to incrementally load your data to an S3 bucket.
To load your data to an S3 bucket:
Copy the following code block:
import snowflake.connector s3_bucket_url = "s3://<your-bucket-name>/path/to/folder/" aws_secret_key = "<your-aws-secret-key>" aws_key_id = "<your-aws-key-id>" # Establish the connection conn = snowflake.connector.connect( account="<your_account>", user="BIGPANDA_VIEWER", password="<your-password>", database="BIGPANDA", schema="<your-schema>", warehouse="BP_READER_WAREHOUSE" ) try: # Create a cursor object cursor = conn.cursor() # Define the date for incremental fetching processing_date = '<2024-06-15>' # Define the COPY INTO command copy_into_query = f""" COPY INTO '{s3_bucket_url}' FROM ( SELECT * FROM "BIGPANDA"."DATA_PLATFORM_1"."INCIDENTS" WHERE processing_date = '{processing_date}' ) CREDENTIALS = ( AWS_SECRET_KEY = '{<aws_secret_key>}' AWS_KEY_ID = '{<aws_key_id>}' ) FILE_FORMAT = ( TYPE = 'CSV' COMPRESSION = 'NONE' FIELD_OPTIONALLY_ENCLOSED_BY = '"' ); """ # Execute the COPY INTO command cursor.execute(copy_into_query) print(f"Data exported to {s3_bucket_url} successfully.") finally: # Close the cursor and connection cursor.close() conn.close()Adjust the
s3_bucket_url,aws_secret_key,aws_key_id,account,password,schema, andprocessing_datevariables.Run the command.
(Optional) Add a catch function to notify you in case of errors.
Load to CSV Using the Python Connector
You can use the Snowflake Connector for Python to incrementally load your data to a CSV file.
To load to CSV:
Copy the following code block:
import snowflake.connector import csv # Establish the connection conn = snowflake.connector.connect( account="<your account>", user="BIGPANDA_VIEWER", password="<your_password>", database="BIGPANDA", schema="<your schema>", warehouse="BP_READER_WAREHOUSE" ) try: # Create a cursor object cursor = conn.cursor() # Define the date for incremental fetching processing_date = '<2024-06-15>' # Execute the query with the processing date query = f""" SELECT * FROM "BIGPANDA"."DATA_PLATFORM_1"."INCIDENTS" WHERE processing_date = '{processing_date}' """ cursor.execute(query) # Fetch the results results = cursor.fetchall() # Get column names column_names = [desc[0] for desc in cursor.description] # Define the CSV file name csv_file_name = '<yourfilename.csv>' # Write results to CSV with open(csv_file_name, mode='w', newline='') as file: writer = csv.writer(file) # Write the column headers writer.writerow(column_names) # Write the data writer.writerows(results) print(f"Data exported to {csv_file_name} successfully.") finally: # Close the cursor and connection cursor.close() conn.close()Adjust the
account,password,schema,processing_date, andcsv_file_namevariables in the code block.Run the command.
(Optional) Add a catch function to notify you in case of errors.
Manage Network Policy and Multi-Factor Authentication
Once the BigPanda support team has provided your organization with a Snowflake Reader user account with the BP_SECURITY_ADMIN role, that account can manage your network policies and multi-factor authentication.
By default, users can connect to the Open Analytics Hub from any computer or device. Users with the BP_SECURITY_ADMIN role can use a network policy to control access to the Open Analytics Hub based on IP addresses.
Security
To increase security, we highly recommend setting up a network policy as a first step after your account is created.
To set up a network policy:
Within the Open Analytics Hub, navigate to Projects > Worksheets.
Select +, and then select SQL Worksheet.
Write and execute the following queries in the worksheet:
CREATE NETWORK POLICY <policy_name> ALLOWED_IP_LIST = ('ip1', 'ip2', ...);ALTER USER BIGPANDA_VIEWER SET NETWORK_POLICY = <policy_name>;
Execute the SHOW PARAMETERS query to identify which network policy is activated at the user level:
SHOW PARAMETERS LIKE 'network_policy' IN USER BIGPANDA_VIEWER;
See Snowflake's Network Policies documentation for more information.
Multi-factor authentication
To increase account security, we highly recommend setting up multi-factor authentication. See Snowflake's Multi-factor authentication (MFA) documentation for details.
Schema
Each of the tables below are available in the Open Analytics Hub for query and export:
ALERTS - Each alert is the aggregated group of each alert status update and changes in BigPanda.
ALERT_PROCESSING - All tags of an alert with normalized fields.
INCIDENTS - A single BigPanda incident.
INCIDENT_ACTIVITIES - A single action a user performed in BigPanda.
INCIDENT_PROCESSING - Pre-aggregated metric totals for Time to Assign, Detect, or Resolve (TTA, TTD, and TTR).
INCIDENT_START_DATE - Date table provided to enable multiple time zone support.
MAINTENANCE_EVENTS - BigPanda events that matched a maintenance plan.
MAINTENANCE_PLANS - A single maintenance plan used to silence alerts in BigPanda.
MTBF - Mean Time Between Failures.
USERS - User who performs an action on an incident.
ENVIRONMENTS - BigPanda Environments group related incidents together for improved automation and visibility.
EVENT_COUNT - The number of BigPanda events.
For details on the fields and primary keys for each table, see the Standard Data Model documentation.
Next Steps
Learn more about the Standard Data Model.
Visualize trends in your data using Unified Analytics.
Learn about the Unified Analytics Standard Dashboards available to all organizations.