Events to Incidents Lifecycle
An event is a point in time that represents the state of a service, application, or infrastructure component. Monitoring tools can generate events when potential problems are detected in your infrastructure.
BigPanda aggregates, normalizes, and enriches events collected from fragmented tools and correlates that data into actionable insights. The platform allows you to detect incidents as they form, in real time, before they escalate into outages.
The BigPanda event lifecycle includes the following event types and actions:
Event Ingestion
Event Deduplication
Event Filtering
Post Dedupe Events
Alert Formation
Incident Formation
Incident Enrichment
Incident Classification
Events to Incidents Flow
 |
Events to incidents flow
Events enter BigPanda during the Event Ingestion stage.
Events are deduplicated and filtered.
Events are aggregated into alerts.
Alerts are further enriched and correlated into incidents.
Incidents are grouped into environments.
View the details below to learn more about how incidents are formed from events in BigPanda.
Event Ingestion
The process starts when BigPanda receives event data from your monitoring applications. Monitoring integrations allow BigPanda to receive alerts from systems such as Nagios, SolarWinds, and AppDynamics. When events first enter BigPanda, they are considered raw events. See Integrate with BigPanda for more information.
Event Deduplication
BigPanda’s built-in deduplication process reduces noise by intelligently parsing incoming raw events. Also known as event deduplication, deduping is the process by which BigPanda eliminates redundant data to reduce noise and simplify incident investigation.
Precise duplicates of existing events are immediately discarded. However, updates to existing alerts are merged rather than creating a brand new alert.
Exact duplicate matches add clutter to the system and are not actionable. If BigPanda receives two or more event payloads where the entire payload exactly matches, the event will be deduplicated and not shown in the UI.
Event Filtering
BigPanda gives users the ability to filter out or suppress events generated for nodes or CIs that are under maintenance, in non-production environments, or that match other special circumstances where operators don’t need to be notified of potential outages or incidents.
Event Filtering in BigPanda is used to filter for events that are unactionable and would only add clutter in BigPanda. The event filter uses BigPanda Query Language to define criteria for events that will be dropped upon ingestion and never be visible in the Incident feed.
Below are some examples of events that you might want filtered:
Misconfiguration (events that are missing tags that are critical for assignment and prioritization, making it impossible to triage)
Lowest severity (events that signal system issues that don’t need to be actioned)
Non-Prod (events from Dev/QA environments)
Non-alerts (info events, logs, etc.)
See the Manage Alert Filtering documentation for more information.
Post-Dedupe Events
Post-dedupe events are the number of events that exist after deduplication and event filtering has been taken into account. This is the number of events prior to alert formation, and incident creation.
Post-dedupe event number
After event ingestion, events are aggregated and formed into alerts. The number of post-dedupe events is generally higher than the number of alerts because the alert creation process includes the aggregation of multiple update events into single alerts.
Alert Formation
Post-dedupe events are clustered into alerts, which represent a single issue within your environment.
Monitoring tools generate events when potential problems are detected in your infrastructure. Over time status updates and repeat events may occur from the same system issue. In BigPanda, raw event data is merged into a singular alert so that you can visualize the life cycle of a detected issue over time.
Alerts in BigPanda are the events that are ingested following deduplication, event filtering, and event aggregation.
Alert Enrichment
BigPanda uses alert tags to add key contextual information to your alerts. Tags drive alert normalization and deduplication, correlation into incidents, incident enrichment, and automation. For more information, see Manage Alert Enrichment.
Incident Formation
An incident is the correlation of one or more alerts that represent an issue that can impact the business through a service disruption. It represents a high-level issue in your system.
A single production issue often manifests itself in multiple alerts. For example, a disk issue can trigger a disk IO alert that, in turn, triggers a series of CPU, memory, database, and application alerts. Additionally, each alert may change as an issue progresses. An alert may start as a warning, and then increase in severity to a critical status. In these cases, diagnosing and fixing the issue requires up-to-date information from multiple sources, which is very difficult to gather and maintain manually.
BigPanda digests all the raw data from your integrated monitoring systems and automatically correlates this complex data into single-issue incidents, giving you the visibility you need to investigate and resolve issues quickly.
After an incident is formed, operators can quickly view and take action within the Incident Feed. For more information about the actions that can be taken on incidents, see Triage Incidents and Remediate Incidents.
Alert Correlation
BigPanda uses correlation patterns to group similar alerts into the same incident. Correlation patterns cluster alerts together based on source system, tags, time window, and (optionally) a customizable query filter. Alert correlation patterns can be created and customized to fit the needs of your organization. For more information, see Manage Alert Correlation.
Max correlation limit
BigPanda can correlate a maximum of 300 alerts into a single incident.
Alert Correlation Steps
Once alerts have been normalized and enriched, the process of correlating them into incidents begins. The following steps are taken as part of the alert correlation process:
1. Check for Matching Alerts
BigPanda checks to see if the new event matches an existing alert in an incident. The system checks the event incident key to determine if the event is a match.
If the event properties match an alert in an active or recently resolved incident, the event is added to that incident as an alert.
If the new event status changes (For example, Warning to Critical), the tag values will be merged into the last event.
2. Check for Matching Correlation Patterns
BigPanda checks to see if the event matches any active correlation patterns. If the event matches, it is added as an alert to an existing incident. If more than one correlation pattern matches, the pattern with the largest correlation window is selected. The incident’s active correlation patterns are updated to include only patterns that apply to all active alerts.
If the event does not match an active correlation pattern, a new incident is created.
3. The Incident Correlation Patterns Are Updated
The incident’s active correlation pattern matches are updated to include only the patterns that apply to all active alerts. Any of the incident’s pattern matches that are no longer in the correlation window are deactivated.
Deactivated Patterns
It’s possible for an alert to be added to an incident even if it does not match some of the active matched patterns. When this happens, the patterns that do not match are deactivated. Deactivated patterns remain attached to the incident, but alerts are no longer correlated into the incident based on these matches.
4. The Incident Title is Updated
The incident title is updated based on the active matched pattern with the largest correlation window.
If the incident has only one alert, the title is generated based on the primary and secondary properties of the active alert.
If the incident has multiple active alerts, the title is generated based on the correlation tags of the pattern with the largest correlation window.
Incident titles can change as alerts join the incident and change status.
5. The Incident Status is Updated
The incident status is updated based on the status of the most severe active alert.
Incident Enrichment
Incident Enrichment in BigPanda is powered by incident metadata and incident tags. Incident tags are created by taking raw data from your systems and normalizing it into key-value pairs. Each tag has two parts: the tag name and the tag value. Tags are the fundamental data model for your alerts and incidents and provide vital incident enrichment.
Incident tags allow you to quickly see summary information for a particular incident rather than needing to review all of the related alerts. Incident tags can leverage any available information that may aid in resolution, such as the cluster and data center where an object resides or links to relevant time series metrics and runbooks.
For more information, see Manage Incident Enrichment.
Incident Classification
After incidents are formed, BigPanda classifies them into related groups for visibility and automation.
Incident environments
A single incident can appear in multiple environments in BigPanda.
Environments filter incidents on properties such as source and priority and group them together for easy visibility and action. Environments make it easy for your team to focus on the incidents relevant to their role and responsibilities. Environments can be used to filter the incident feed, or can be used to create dashboards, set up sharing rules, and simplify incident search.
See Manage Environments for more information.
Incident Life Cycle Logic
The life cycle of an incident is defined by the life cycle of the alerts it contains. An incident remains active if at least one of the alerts is active, is automatically resolved when all the alerts are resolved, and is reopened when a resolved alert becomes active again.
Time Based Alert Resolution
The Time Based Alert Resolution feature will automatically resolve orphaned or outstanding alerts, allowing for easy noise reduction and increased MTTR. For more information, see the Time-Based Alert Resolution documentation.
Alert/Incident Statuses
The incident timeline shows status changes along the Status line. Status changes are marked using colored dots and lines.
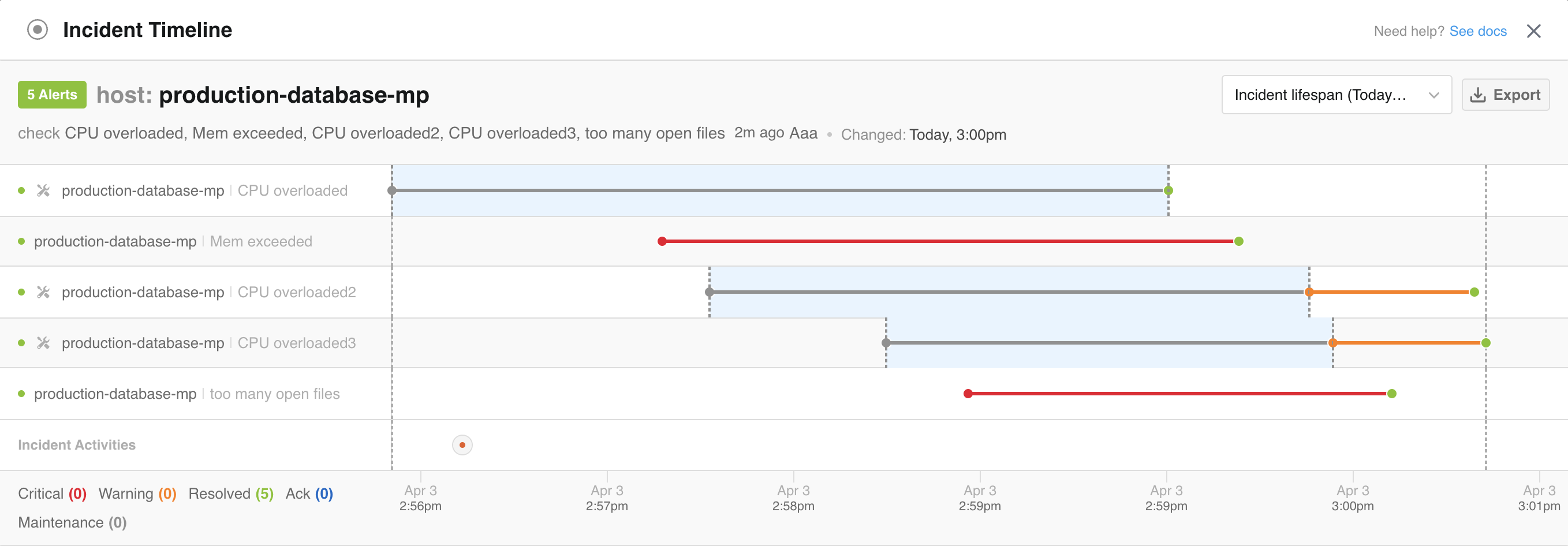
Icon | Description |
|---|---|
Orange dot | The alert is in Warning status. |
Red dot | The alert is in Critical status. |
Green dot | The alert was resolved. |
Black and grey circles | The alert was marked as flapping. |
Grey dot | The status is unknown. |
Dotted line | The alert is in maintenance. The status line will also be highlighted in light blue for the duration of the maintenance period. |
Blue dot | The alert was acknowledged |
Additional incident actions are shown along the Activities line.

Timeline Activity Icons
Icon | Description |
|---|---|
Orange bust with plus | The incident was assigned to a user. |
Blue arrow | The incident was manually or automatically shared. |
Grey up and down arrows | The incident priority was manually updated. |
Grey up and down arrows with a line through them | The incident priority was manually removed. |
Yellow dialogue bubble | A comment was added to the incident. |
Orange bell | The incident was snoozed. |
Grey paragraph lines | A value was manually changed for a single-value tag. |
Grey bullet point lines | A value was manually added, changed, or removed for a multi-value tag. |
Green checkmark | The incident was manually resolved, or one of the included alerts was manually or automatically resolved. |
Alert Resolution and Closing Statuses
An incident remains open as long as at least one of the alerts associated with it is open. When BigPanda receives an event with a status of ok, the related alert is automatically resolved.
Alerts that have not been resolved remain open in BigPanda. The corresponding incident also remains open and continues to appear in the Incident Feed.
Resolving Alerts with the Alerts REST API
To maintain only the most relevant information in the incident feed, send a resolving event to BigPanda using the Alerts REST API when an alert is no longer active.
Reopen Incidents
Resolved incidents are reopened when any of the alerts associated with them reopen. This rule applies regardless of how the incident was resolved—manually, due to inactivity, or automatically when all associated alerts were resolved.
By default, alerts are reopened if they reoccur within a 60 minute timeframe of when they were resolved. If an alert reoccurs more than 60 minutes later, it is handled as a new alert.
Snoozed Incidents Exception
The incident will also reopen if a new event that matches one of the correlation patterns of the incident comes in. Incidents that are more than 30 days old are never reopened. If the associated alerts reoccur, a new incident is created.
Reopen Window
The time frame of the reopen window can be customized to fit your monitoring needs, up to a max entity age of 30 days. Keep in mind this is a global setting that impacts all incidents. Please contact your BigPanda Support and request a product change if you'd like to change the time frame for incident reopening.
Flapping Incidents
Flapping occurs when a monitored object (ie: a service or host) changes state too frequently, making the cause and severity of the incident unclear. For example, flapping can be indicative of configuration problems (ie: thresholds set too low), troublesome services, or real network problems.
When an alert changes states frequently, it may generate numerous events that are not immediately actionable. In the example timeline shown below, you can see how hundreds of potential notifications are grouped into one incident for the application that is flapping.
In BigPanda, an incident enters the flapping state when one or more of the related alerts are flapping. By default, an alert is considered to be flapping when it has changed states more than 4 times in one hour. Contact BigPanda Support and request a product change if you need to configure custom logic (number of state changes within a period of time) for your organization or for a specific integration.
When an incident enters the flapping state, all subscribed integrations are notified and no additional state change notifications are sent. Email integrations will send a daily email reminding users about the incident. An incident exits the flapping state when all related alerts stop flapping (no longer meet the criteria for number of state changes in a period of time). BigPanda checks the flapping criteria every 15 minutes.
You can see if an incident is in a flapping state in the incident feed, alerts table, activity feed, and in the timeline.
Flapping indicator in the Incident Feed
Flapping indicators in the Alerts table and Activity feed
Next Steps
Learn more about Incidents in BigPanda.
Find steps to Triage Incidents in BigPanda.
Learn how to Remediate Incidents.